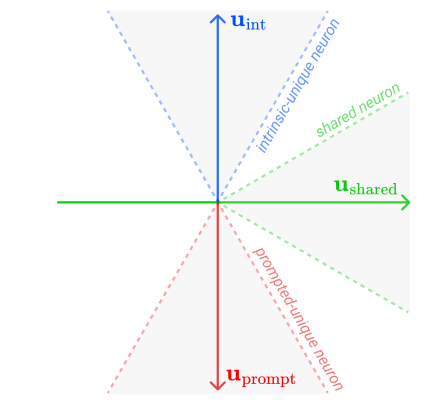
Vector-level view
Value vectors capture activation directions associated with expressing each Schwartz value.
ICML 2026 Regular Paper
Intrinsic vs. Prompted Values in Large Language Models
*Equal contribution. †Corresponding author.
This paper asks whether values that emerge from a model's learned behavior and values requested by a prompt use the same internal mechanisms. They partially overlap, but the intrinsic parts support more natural and diverse value expression, while the prompted parts act more like direct instruction-following control.
A language model can express a value even when the prompt does not explicitly ask for one: for example, its answer may naturally favor benevolence, security, or tradition. A model can also express a value because the prompt directly asks it to. This paper separates these two cases as intrinsic value expression and prompted value expression, then asks whether they rely on the same internal machinery. The analysis uses activation directions and MLP neurons to compare where the two mechanisms overlap and where they split apart.
Introduction
Prompting is a common way to make language models express particular values, but that does not mean the prompted expression uses the same mechanism as the model's learned value tendencies. This paper compares intrinsic and prompted expression at the level of activation directions and MLP neurons.
Value vectors capture activation directions associated with expressing each Schwartz value.
Value neurons identify MLP components whose output directions contribute to those value directions.
Steering experiments test whether shared and unique components produce different behavior.
Method
The method extracts value directions from residual stream activations and then attributes those directions to MLP neurons, separating shared and mechanism-specific components.
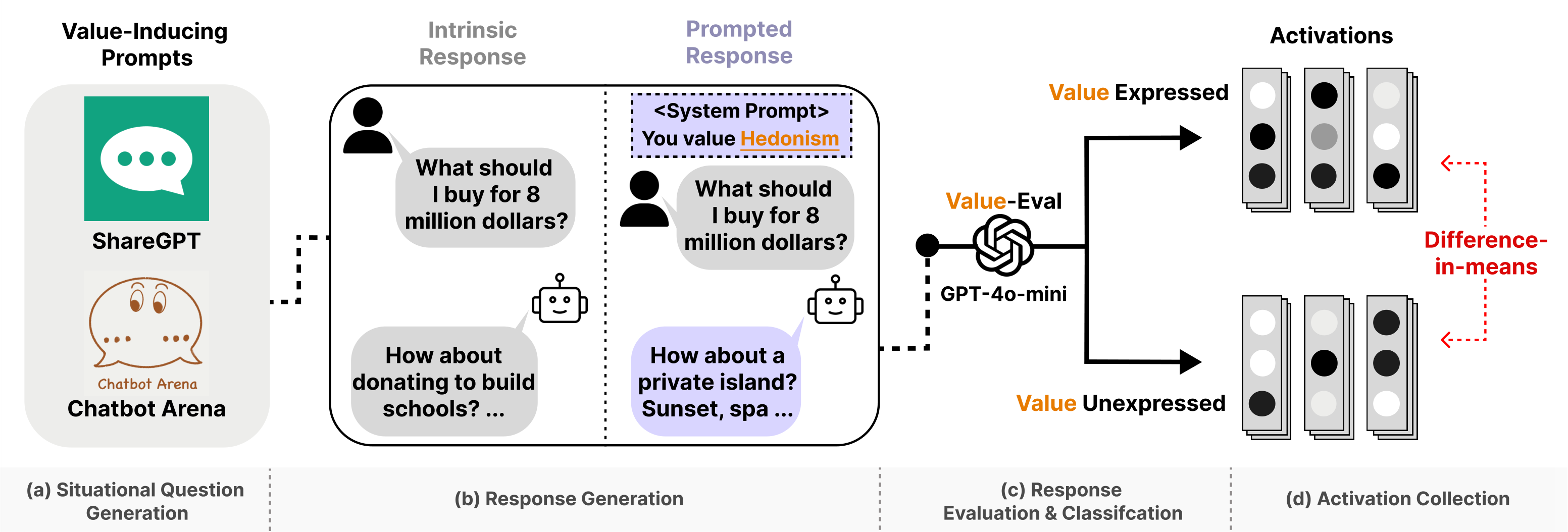
Collect intrinsic responses without value prompts and prompted responses with value-targeting prompts.
Classify whether each response expresses the target value, producing expressed and unexpressed sets.
Compute difference-in-means directions from residual stream activations.
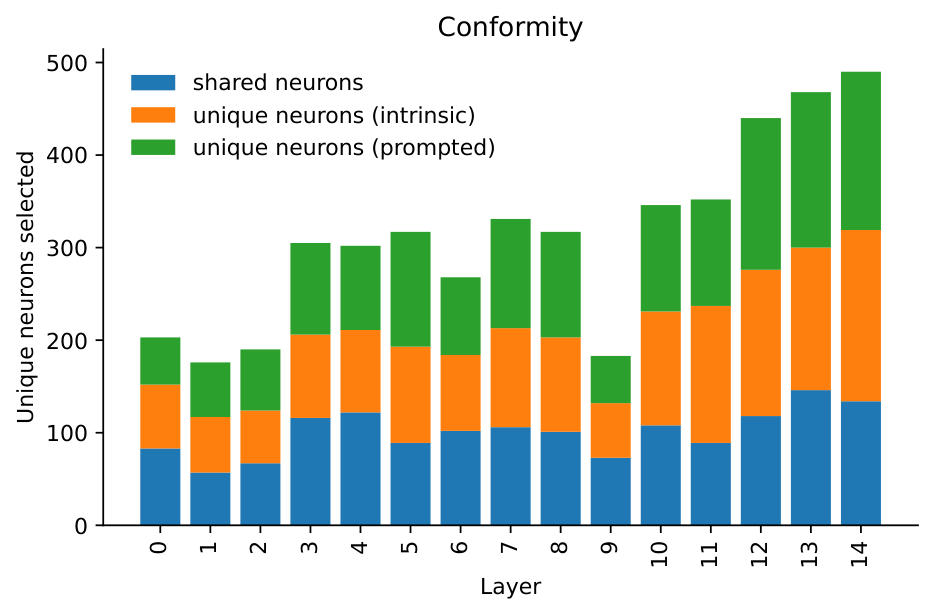
Classify neurons by alignment with shared, intrinsic-unique, and prompted-unique axes.
Evidence
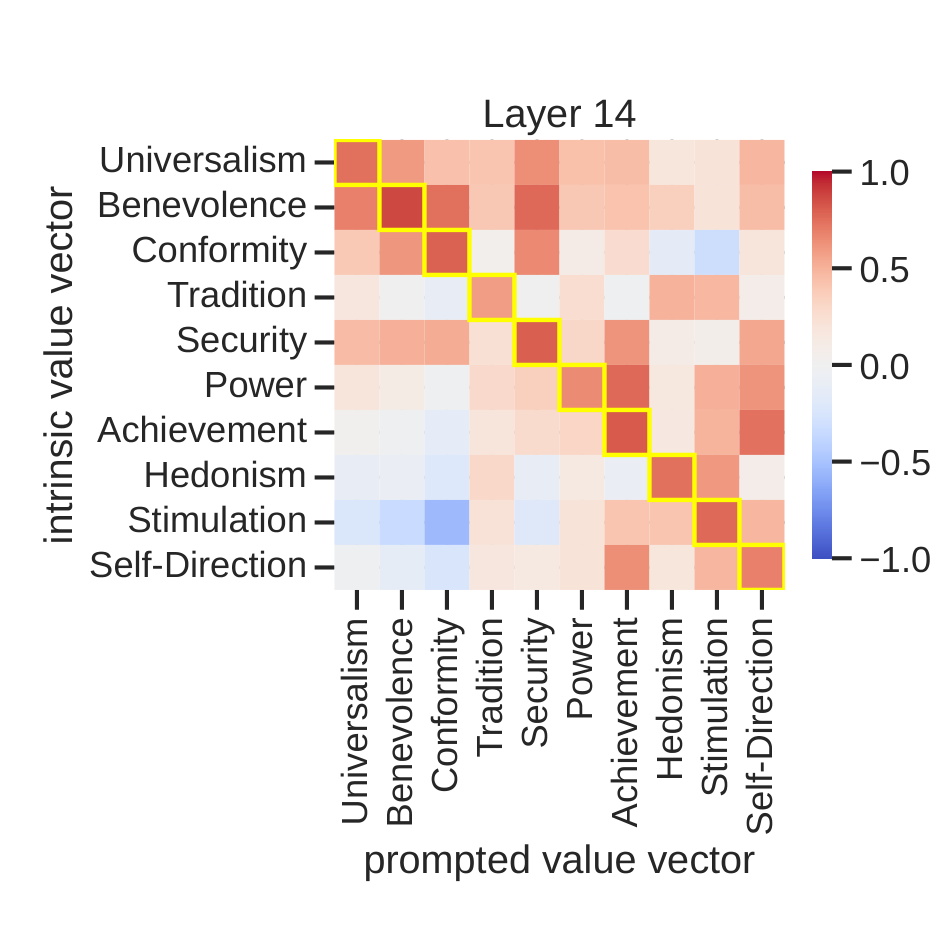
Intrinsic and prompted value representations show meaningful similarity, but the non-overlapping components are large enough to create different behavioral effects.
Behavior
The paper finds a consistent tradeoff: prompted mechanisms are more directly steerable, while intrinsic mechanisms produce more lexically diverse responses.
Mean score delta over five languages and ten Schwartz values with Qwen2.5-7B-Instruct.
Prompted steering remains slightly stronger in open-ended value expression.
Intrinsic steering uses a broader set of lexical choices in English situational dilemmas.
The diversity advantage persists across multiple lexical and semantic metrics.
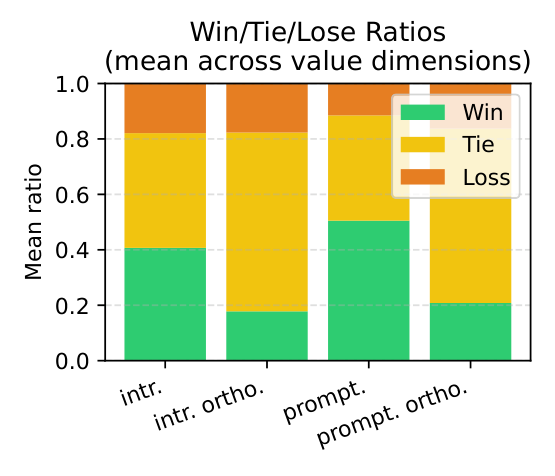
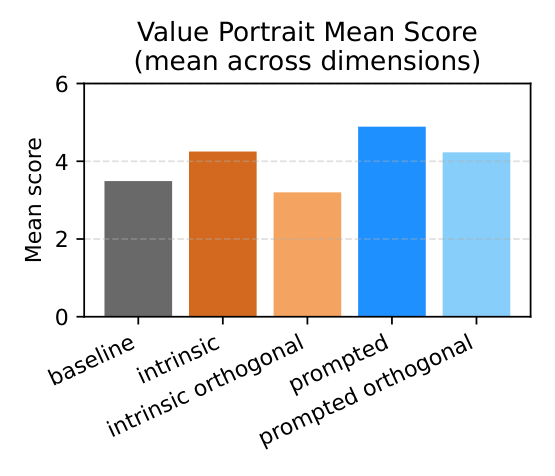
Analysis
Shared components recover the structure of human values, while unique components explain the tradeoff between natural value expression and direct instruction compliance.
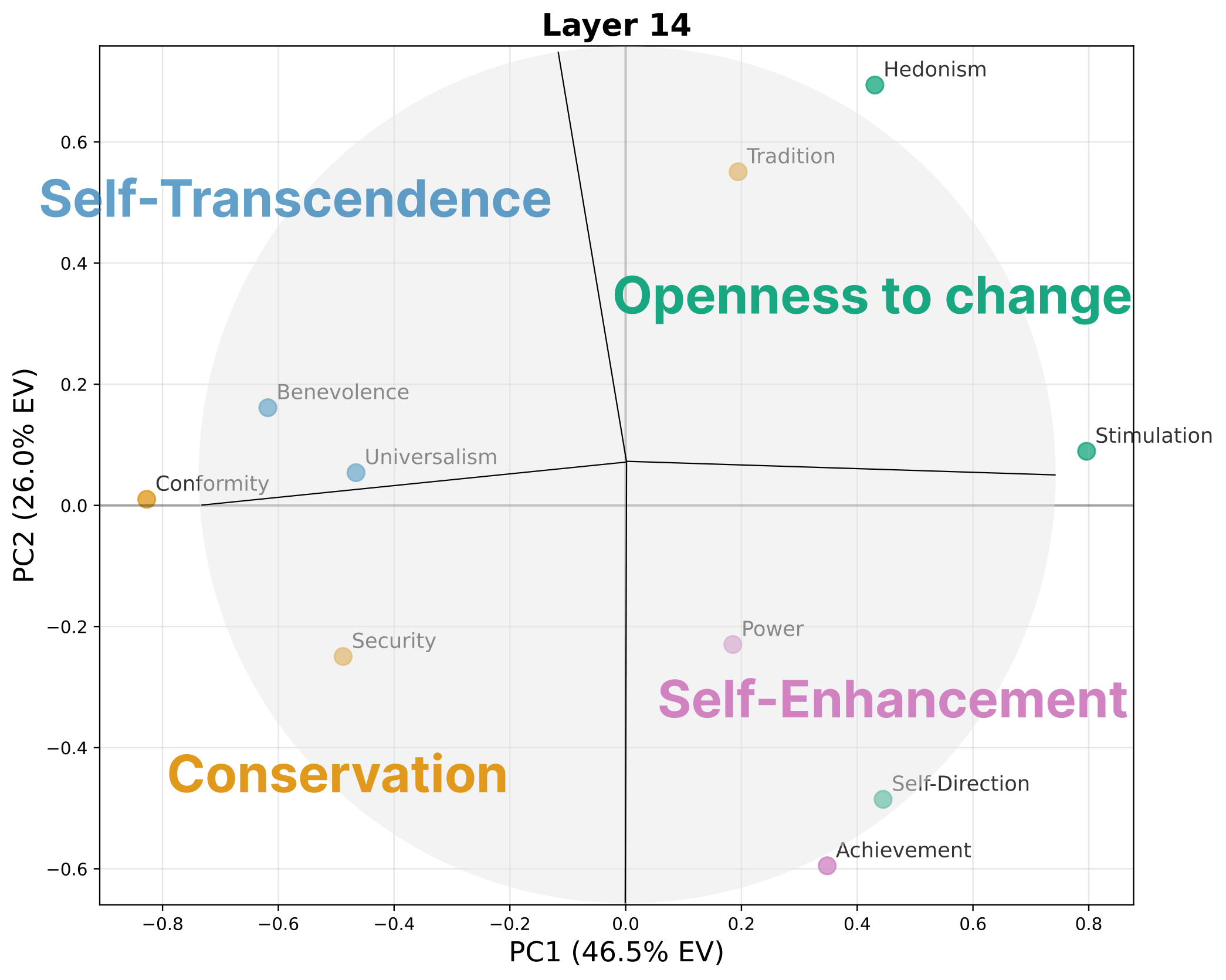
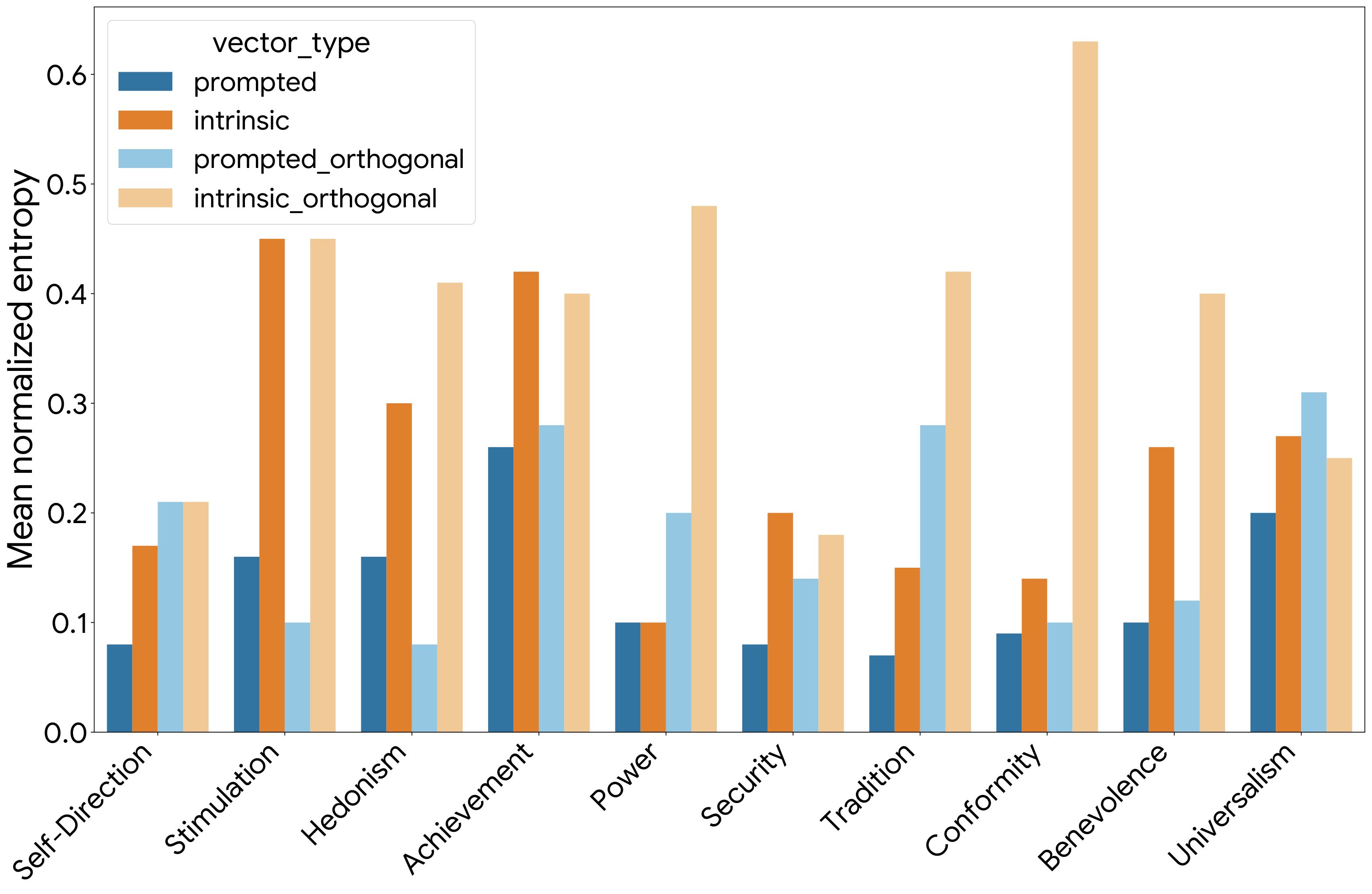
The prompted-unique component also behaves like a broader instruction-following channel, which makes the mechanism relevant for transparency and safety analysis beyond value expression.
BibTeX
This BibTeX entry includes the arXiv identifier and ICML 2026 status.
@misc{han2026dualmechanisms,
title = {Dual Mechanisms of Value Expression: Intrinsic vs. Prompted Values in Large Language Models},
author = {Jongwook Han and Jongwon Lim and Injin Kong and Yohan Jo},
year = {2026},
eprint = {2509.24319},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
note = {ICML 2026 Regular Paper}
}